懒汉
第一次调用时实例化
1 | public class LHanDanli { |
双重判断
不用每次获取对象都加锁
volatile 屏蔽虚拟机代码优化(代码执行顺序),运行效率会成问题
1 | public class SLHanDanli { |
饿汉
加载类内就实例化
第一次调用时实例化
1 | public class LHanDanli { |
不用每次获取对象都加锁
volatile 屏蔽虚拟机代码优化(代码执行顺序),运行效率会成问题
1 | public class SLHanDanli { |
加载类内就实例化
1 | sudo service docker status |
1 | docker search Python |
1 | docker pull python:2.7 |
镜像 image
1 | docker images |
容器 container
1 | docker ps #run container |
1 | docker logs -f <container or id> |
-f或--follow选项表示跟随日志输出,即持续显示新的日志条目。-t或--timestamps选项会在每条日志前添加时间戳,以便于追踪日志的时间顺序。
--tail参数用于限制返回的日志行数,只显示最新的 N 条日志记录
1 | docker inspect <id> |
1 | sed [options] 'command' file(s) |
g 表示行内全面替换。 global 全局
p 表示打印行。 P 打印模板第一行
r 读文件
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法) -i :直接修改读取的文件内容,而不是输出到终端
w 表示把行写入一个文件。
x 表示互换模板块中的文本和缓冲区中的文本。
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
\1 子串匹配标记
& 已匹配字符串标记元字符集
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
- 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed。
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
(..) 匹配子串,保存匹配的字符,如s/(love)able/\1rs,loveable被替换成lovers。
& 保存搜索字符用来替换其他字符,如s/love/&/,love这成love。
< 匹配单词的开始,如:/\ 匹配单词的结束,如/love>/匹配包含以love结尾的单词的行。
x{m} 重复字符x,m次,如:/0{5}/匹配包含5个0的行。
x{m,} 重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行。
x{m,n} 重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行。
把目录下所有格式文件内容进行批量替换
1 | sed -n "s#/pics/${src#$dest#g"p `grep /pics/${src -rl --include=\*.{yaml,md} $path` |
扫描path路径对应格式的文件,把src替换成dest,
sed
-n p 结合打印改变内容,不执行变更
grep
-r 表示查找当前目录以及所有子目录
-l 表示仅列出符合条件的文件名
–include=”*.[ch]” 表示仅查找.c、.h文件
上面不适用大多数情况,推荐下面
–include=*.{yaml,md}
在两台计算机相互传递信息时,HTTP规定了每段数据以什么形式表达才是能够被另外一台计算机理解
第一步:在浏览器输入内容(网址)
第二步:浏览器把 域名 发送到DNS上 ,进行解析 得到IP之后链接到指定
服务器 (服务器地址110,102.13.32:80 从浏览器到服务器使用底层TCP/IP)
第三步:实现TCP/IP协议用Socket 用Socket套接字
第四步:服务器端口80监听客户端链接(客户端到服务器端链接)
HTTP 1.0 一个链接发送一个请求
HTTP 1.1 一个链接发送多个请求
get 向服务器 【索取】 数据的一种 请求
一般用于 获取/查询 资源信息
get用于信息获取,而且应该是安全(指非修改信息)和幂等
如:新闻头版不断更新,该操作被认为安全和幂等,从自身角度来看没有改变资源
post 向服务器 【提交】 数据的一种 请求
一般用于 更新 资源信息
post表示可能修改服务器上的资源请求
如:评论新闻,提交后站点资源不同,资源被修改
表面现象
get请求数据附在URL上; post提交数据放在http包体中
get字节限制(1024) 实质是浏览器(和服务器)的限制 ; post理论没有限制
post 安全(security)性比 get安全(security)性高
规定的是数据应该怎么传输才能稳定且高效的传递与计算机之间。
| \ | TCP | UDP |
|---|---|---|
| 是否连接 | 面向连接 | 面向非连接 |
| 传输可靠性 | 可靠 | 不可靠 |
| 应用场合 | 传输大量的数据,对可靠性要求较高的场合 | 传送少量数据、对可靠性要求不高的场景 |
| 速度 | 慢 | 快 |
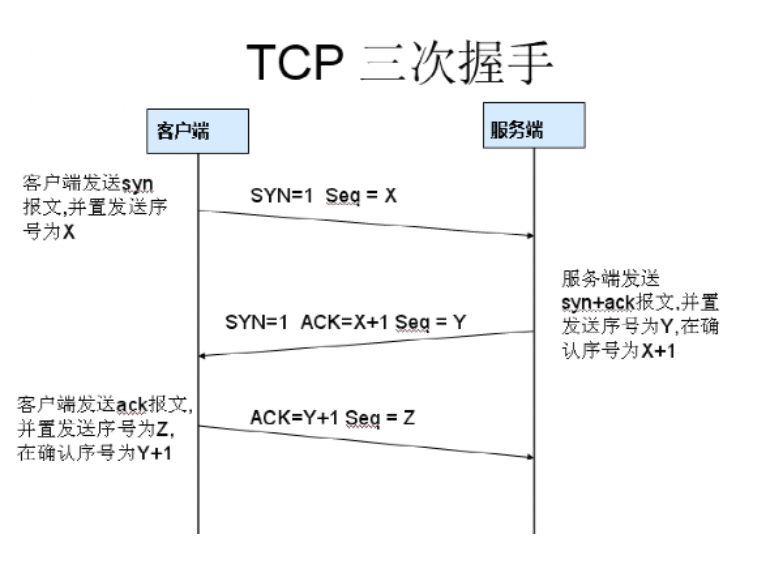
1.客户端发送syn报文,序号seq=X
2.服务发送syn+ack报文,序号seq=y,确认ack=X+1
3.客户端发送ack报文,序号seq=Z ,确认ack=Y+1
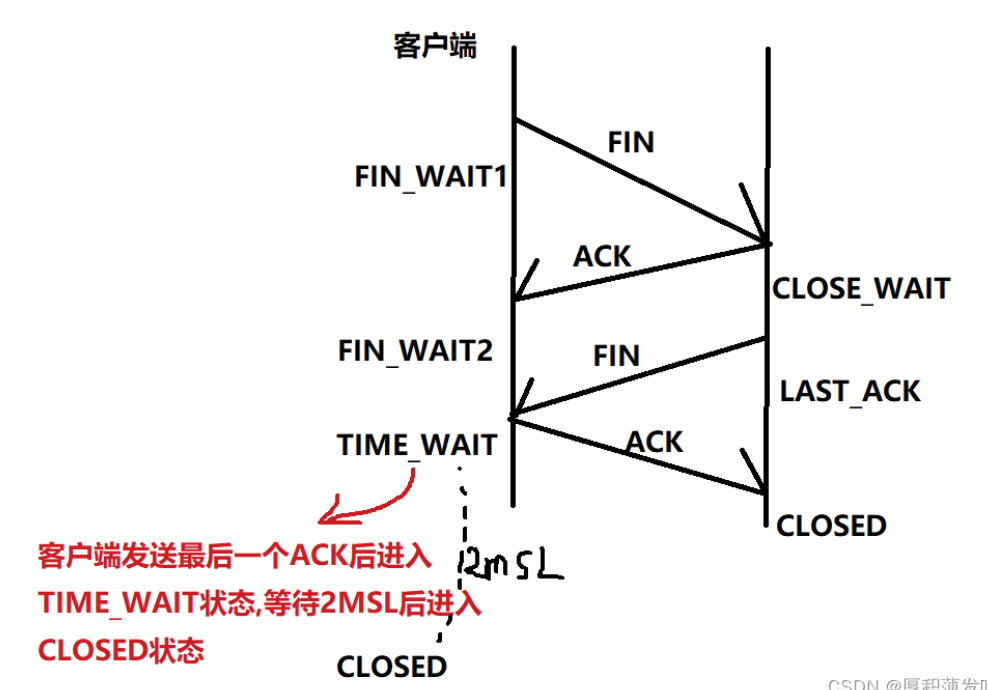
四次挥手的过程可以知道每一方都要发送一个FIN报文和一个ACK报文
服务端发送的ACK报文并不能和FIN报文结合在一起发送,因为要等待服务端进程处理完数据之后才可以关闭连接, 所以是四次挥手.
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议
1 | ❯ sudo apt install tcpdump |
❯ kubectl get pods -o wide -A | grep -E ‘^NAMESPACE|traefik’
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default traefik-7d7459bcdc-js5gc 1/1 Running 0 4h42m 121.21.112.116 k8s08❯ kubectl get pod
traefik-7d7459bcdc-js5gc-o json |grep -C 2 containerID
“containerStatuses”: [
{
“containerID”: “containerd://e11f4f9710a330ba375823e849f32880fe7103e12324ae4d2ec3b7dc9879662b“,
“image”: “k8s.org/k8s/traefik:v2.10.4”,
“imageID”: “k8s.org/k8s/traefik@sha256:57b2516b7549c4f59531bb09311a54a05af237670676529249c3c0b8e58ad0f3”[root@k8s08 ~]# crictl exec
e11f4f9710a330ba375823e849f32880fe7103e12324ae4d2ec3b7dc9879662b/bin/sh -c ‘cat /sys/class/net/eth0/iflink’
DEBU[0000] get runtime connection
DEBU[0000] ExecRequest: &ExecRequest{ContainerId:e11f4f9710a330ba375823e849f32880fe7103e12324ae4d2ec3b7dc9879662b,Cmd:[/bin/sh -c cat /sys/class/net/eth0/iflink],Tty:false,Stdin:false,Stdout:true,Stderr:true,}
DEBU[0000] ExecResponse: &ExecResponse{Url:http://127.0.0.1:41659/exec/u51c3Rnf,}
DEBU[0000] Exec URL: http://127.0.0.1:41659/exec/u51c3Rnf
DEBU[0000] StreamOptions: {0xc000012018 0xc000012020 false } 8
[root@k8s08 ~]# for i in /sys/class/net/veth/ifindex; do grep -l8$i; done*
/sys/class/net/veth2e926487/ifindex[root@k8s08 ~]# sudo tcpdump -i veth91f5a7d7 -w ~/tcpdump.cap
1 | tcpdump -r large.pcap -w part1.pcap -c 1000 -s 0 |
-c 包的数量
-s 0 捕获整个数据包,不截断包
1 | tcpdump -r large.pcap -w part1.pcap -c 50000 |
-j选项后面跟的是跳过的包数,用于分割下一个文件
split cap
import pyshark
def split_pcap(input_file, output_prefix, packets_per_file):
cap = pyshark.FileCapture(input_file)
file_number = 1
with open(f"{output_prefix}{file_number}.pcap", "wb") as f:
for packet in cap:
f.write(packet.data)
if cap.count() % packets_per_file == 0:
file_number += 1
f.close()
with open(f"{output_prefix}{file_number}.pcap", "wb") as f:
continue
# 调用函数
split_pcap('large.pcap', 'part', 50000)
== ! && or
1 | tcp.port==80 && ip.src == 192.168.56.116 |
https://www.npmjs.com/package/npm
设置
1 | echo "registry = https://registry.npm.taobao.org">>~/.npmrc |
查看当前源
1 | npm config get registry |