go env
编译二进制
You have a working Go environment.
1 | GOPATH=`go env | grep GOPATH | cut -d '"' -f 2 ` |
$GOPATH/go.mod exists but should not #开启模块支持后,并不能与GOPATH共存 ,所以把GOPATH置空
go mod vendor
前置条件配置
- 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
- 每台机器
2 GB或更多的 RAM (如果少于这个数字将会影响你应用的运行内存) 2 CPU核或更多- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 开启机器上的某些端口。请参见这里 了解更多详细信息。
- 禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区
更多见 https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
2种 HA 集群方式
文档 https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/ha-topology/
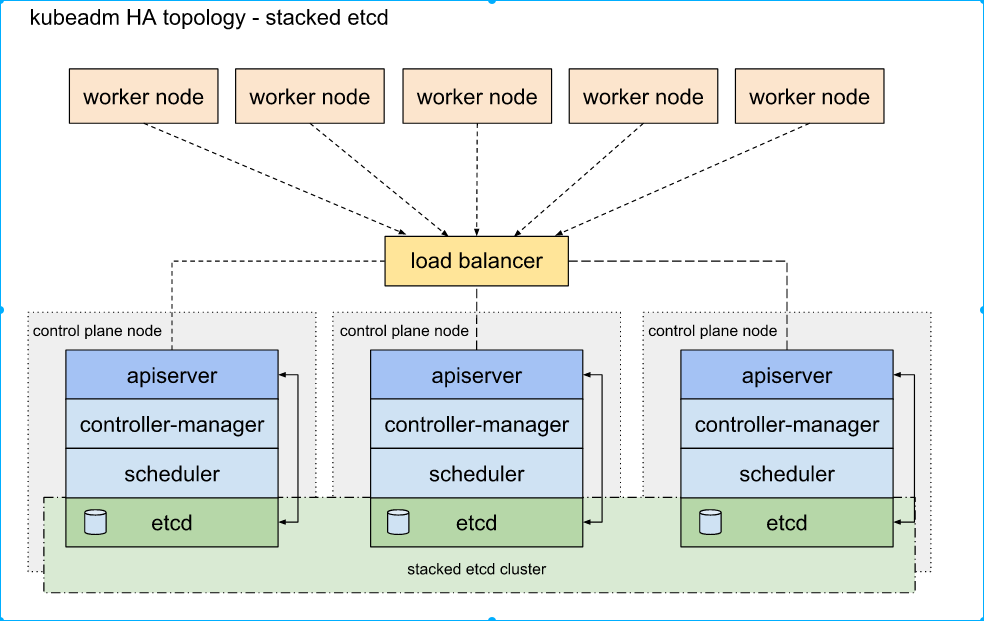
堆叠(Stacked)etcd
这种拓扑将控制平面和 etcd 成员耦合在同一节点上,设置简单.存在耦合失败的风险
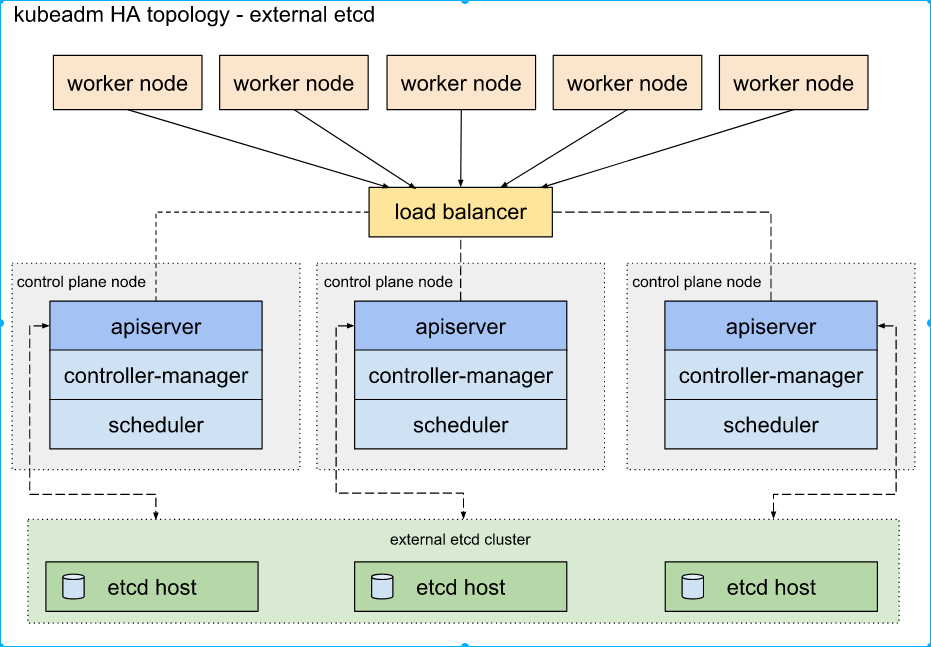
外部 etcd 节点
这种拓扑结构解耦了控制平面和 etcd 成员.需要两倍于堆叠 HA 拓扑的主机数量
组件
master
master组件使用容器pod部署,需要部署kubelet组件,拉起静态容器组件
etcd
角色:kv存储,保存集群状态和配置信息
存储集群的整体状态、配置信息和元数据,被 kube-apiserver 用于存储配置信息、Pod 状态、Service 数据等原理:
kube-apiserver
角色:提供集群入口,处理api请求(例如认证,crud操作)
接受客户端(例如kubectl,,ui)和其他组件请求,校验请求,转发到其他组件
kube-scheduler
角色:将创建pod调度到合适节点
监听未调度的pod,考虑资源约束,硬件要求,选择将合适节点将pod信息反馈给apiserver
kube-controller-manager
角色:包含多个控制器,负责维护集群各种资源的状态
监听apiserver中资源的变化,如Replication Controller(用作Deployment协调创建、删除和更新Pod) ,node controller等,通过 API Server 更新集群状态以达到期望的状态。
kubelet
角色:每个node节点部署,负责维护pod的生命周期
其他组件静态pod形式,kubelet 拉起
node
kubelet
角色:每个node节点部署,负责维护pod的生命周期
从 API Server 获取 Pod 的期望状态,与容器运行时(如 Docker,Containerd)交互,管理 Pod 的创建、启动、停止,并将节点状态报告给 API Server。
kube-proxy
角色:提供网络代理和负载均衡服务,确保pod内外流量路由正确
监听 API Server 中 Service 和 Endpoint 的变化,维护节点上的网络规则,确保流量正确地到达后端的 Pod。
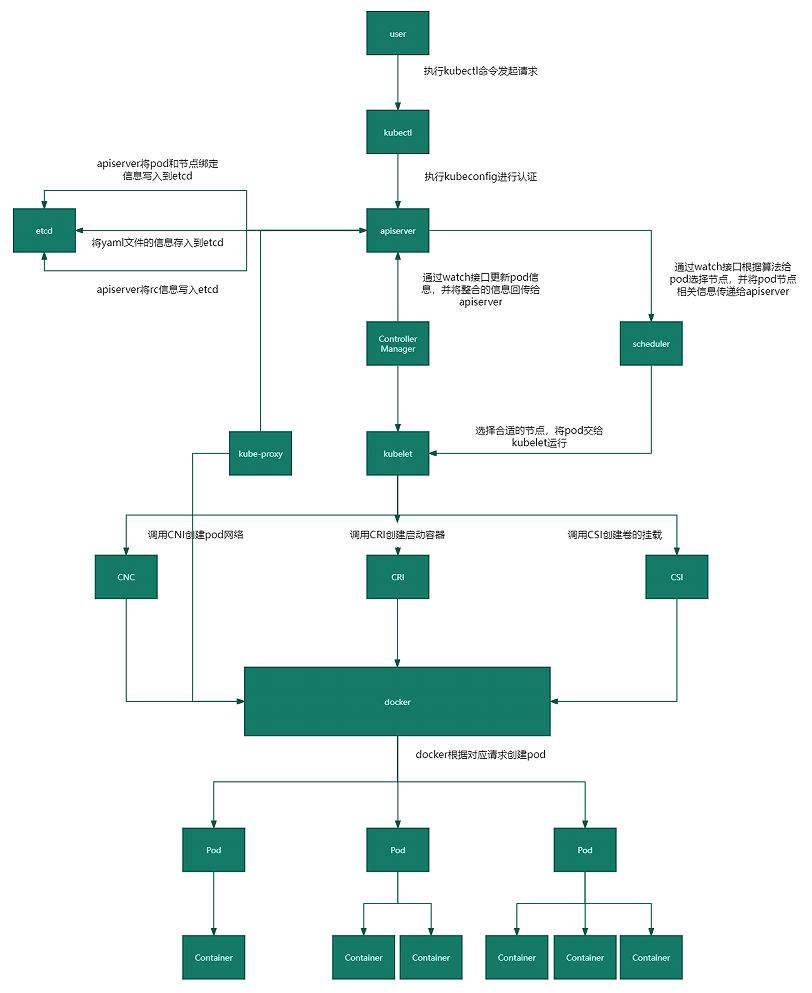
- 用户通过kubectl向api-server发起创建pod请求。
- apiserver通过对应的kubeconfig进行认证,认证通过后将yaml中的po信息存到etcd。
- Controller-Manager通过apiserver的watch接口发现了pod信息的更新,执行该资源所依赖的拓扑结构整合,整合后将对应的信息交给apiserver,apiserver写到etcd,此时pod已经可以被调度。
- Scheduler同样通过apiserver的watch接口更新到pod可以被调度,通过算法给pod分配合适的node,并将pod和对应节点绑定的信息交给apiserver,apiserver写到etcd,然后将pod交给kubelet。
- kubelet收到pod后,k8s调用标准接口与docker交互(调用CNI接口给pod创建pod网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载),Docker 提供了容器的运行时环境,负责启动、停止、管理容器的生命周期。kubelet 通过与 Docker 通信,使用 Docker 的 API 来创建和管理容器。
- 网络,容器,存储创建完成后pod创建完成,等业务进程启动后,pod运行成功。
pod
探测
策略
restartPolicy有三个可选值:
Always:当容器终止退出后,总是重启容器,默认策略。OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。Never:当容器终止退出,从不重启容器。
三种方式
exec
- (自定义健康检查):在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
1 | livenessProbe: |
如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的,返回非 0 值,kubelet 会执行
restartPolicy策略
httpGet
- 通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器 健康。
1 | ports: |
发送一个 HTTP GET 请求来执行探测,处理程序返回成功代码(大于或等于
200并且小于400),则 kubelet 认为容器是健康存活的,否则kubelet 会执行restartPolicy策略
tcpSocket
- 通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
1 | readinessProbe: |
探针种类
1 | apiVersion: v1 |
initialDelaySeconds:容器启动后等待多少秒才开始执行探针。periodSeconds:探针执行的间隔时间。timeoutSeconds:探针超时时间。successThreshold:最小连续成功的探针次数。failureThreshold:连续失败的探针次数,达到这个次数后,将采取相应的行动(如重启容器)。
启动(startupProbe)
启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被前面的探针kill掉。如 java服务
如果匹配了 startupProbes 探测,则在 startupProbes 状态为 Success 之前,其他所有探针都处于无效状态,直到它成功后其他探针才起作用
如果 startupProbe 失败,kubelet 将杀死容器,容器将根据 restartPolicy 来重启。如果容器没有配置 startupProbe,则默认状态为 Success。
就绪(Readiness Probes)
就绪检查,通过readiness是否准备接受流量,准备完毕加入到Endpoint,否则剔除。如果容器不提供就绪探针,则默认状态为 Success。
存活(Liveness Probes)
检查机制,检查应用是否可用,如死锁,无法响应,异常时将根据restartPolicy来设置 Pod 状态会自动重启容器,如果容器不提供存活探针,则默认状态为 Success。
PodDisruptionBudget
- 最小可用(Min Available): 通过指定最小可用Pod数量,确保在中断期间至少有这么多的Pod保持运行。这对于维持服务的基本运行至关重要。
- 最大不可用(Max Unavailable): 通过指定最大不可用Pod数量,限制在中断期间可以被驱逐的Pod数量。这有助于避免大规模的服务中断。
- 选择器(Selector): PDBs使用选择器来确定哪些Pod受到保护。只有匹配选择器的Pod才会受到PDB的限制。
- 优先级(Priority): PDBs可以与
PriorityClass结合使用,为不同优先级的Pod设置不同的中断预算。
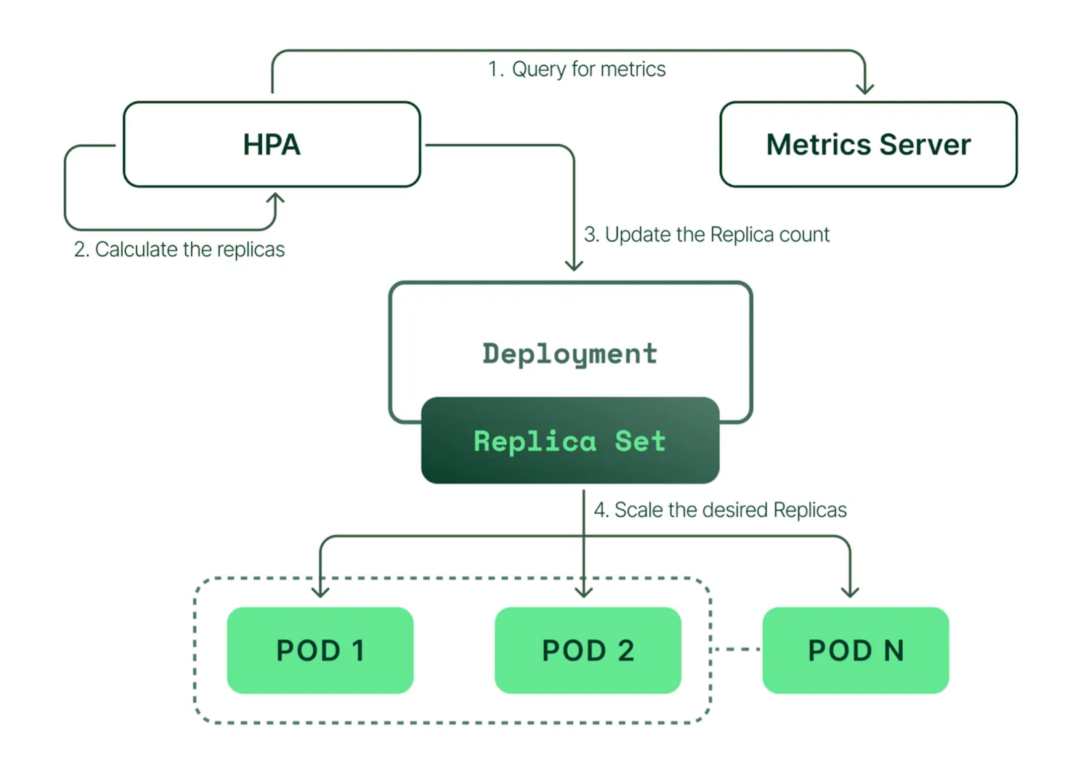
Horizontal Pod Autoscaler(HPA)
hpa-custom_metric.yaml
custom_metric
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app-deployment
minReplicas: 3 #定义最小副本数
maxReplicas: 6
metrics:
- type: Pods
pods:
metric:
name: my_custom_metric
target:
type: AverageValue
averageValue: 100 # 你的自定义指标的目标值
type:
- Resource:这是内置的指标类型,用于根据 Pod 的资源使用情况(如 CPU 或内存)进行自动扩缩。它适用于
autoscaling/v2API 版本或更高版本。- Pods:这种类型的指标是针对每个 Pod 的自定义指标,如请求的速率或网络流量。指标值将针对所有 Pod 进行平均,然后与目标值进行比较。
- Object:这种类型的指标是针对特定的 Kubernetes 对象,如 Ingress 或 PersistentVolume。它使用对象的特定指标来触发扩缩。
- External:这种类型的指标不是来自 Kubernetes 集群内部,而是由外部监控系统(如 Prometheus)提供。它可以用于根据集群外部的度量指标进行扩缩。
- Custom:在某些 Kubernetes 版本中,可能还有
Custom类型的指标,它允许用户定义自己的指标和目标,但这可能需要使用 Kubernetes 的自定义指标 API
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
事件驱动
