cs@debian:~$ kubectl get cs NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-2 Healthy {"health": "true"} etcd-0 Healthy {"health": "true"} etcd-1 Healthy {"health": "true"}
node节点
1 2 3 4 5 6 7 8 9
cs@debian:~$ kubectl get node NAME STATUS ROLES AGE VERSION master02 Ready <none> 101d v1.18.8 master03 Ready <none> 101d v1.18.8 node04 Ready <none> 101d v1.18.8 node05 Ready <none> 101d v1.18.8 node06 Ready <none> 101d v1.18.8
kubectl get node -o wide
空间
1 2 3 4 5 6 7 8
cs@debian:~$ kubectl get namespaces NAME STATUS AGE default Active 101d devops Active 100d kube-node-lease Active 101d kube-public Active 101d kube-system Active 101d kubernetes-dashboard Active 92d
pod
1 2 3 4 5 6 7 8
cs@debian:~$ kubectl get pod No resources found in default namespace.
cs@debian:~$ kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE coredns-56ff7bc666-prc6l 1/1 Running 4 11d coredns-56ff7bc666-qwdsh 1/1 Running 8 92d traefik-ingress-controller-7769cb875-x76rs 1/1 Running 1 46h
-n 接namespaces的NAME值,省略为default
1 2
kubectl get pods -o wide kubectl get pods -A -o wide
cs@debian:~/oss/hexo$ kubectl get pod --field-selector status.podIP=121.21.35.3 -o wide -n devops NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES redis-app-1 1/1 Running 1 9d 121.21.35.3 node04 <none> <none>
$ kubectl get events LAST SEEN TYPE REASON OBJECT MESSAGE 2d18h Normal Starting node/k8s Starting kubelet. 2d18h Normal NodeHasSufficientMemory node/k8s Node k8s status is now: NodeHasSufficientMemory 2d18h Normal NodeHasNoDiskPressure node/k8s Node k8s status is now: NodeHasNoDiskPressure 2d18h Normal NodeHasSufficientPID node/k8s Node k8s status is now: NodeHasSufficientPID 2d18h Normal NodeAllocatableEnforced node/k8s Updated Node Allocatable limit across pods 2d18h Normal Starting node/k8s Starting kubelet. 2d18h Normal NodeHasSufficientMemory node/k8s Node k8s status is now: NodeHasSufficientMemory 2d18h Normal NodeHasNoDiskPressure node/k8s Node k8s status is now: NodeHasNoDiskPressure 2d18h Normal NodeHasSufficientPID node/k8s Node k8s status is now: NodeHasSufficientPID 2d18h Normal NodeAllocatableEnforced node/k8s Updated Node Allocatable limit across pods 2d18h Normal NodeReady node/k8s Node k8s status is now: NodeReady 2d18h Normal RegisteredNode node/k8s Node k8s event: Registered Node k8s in Controller 2d18h Normal Starting node/k8s Starting kube-proxy. 2d18h Normal RegisteredNode node/k8s Node k8s event: Registered Node k8s in Controller 23m Normal Starting node/k8s Starting kubelet. 23m Normal NodeHasSufficientMemory node/k8s Node k8s status is now: NodeHasSufficientMemory 23m Normal NodeHasNoDiskPressure node/k8s Node k8s status is now: NodeHasNoDiskPressure 23m Normal NodeHasSufficientPID node/k8s Node k8s status is now: NodeHasSufficientPID 23m Normal NodeAllocatableEnforced node/k8s Updated Node Allocatable limit across pods 23m Normal Starting node/k8s Starting kube-proxy. 22m Normal RegisteredNode node/k8s Node k8s event: Registered Node k8s in Controller
❯ kubectl debug -it vault-1 -n vault --image=k8s.org/cs/netshoot -- bash Defaulting debug container name to debugger-z9zr4. If you don't see a command prompt, try pressing enter. vault-1:/root$
service ping不通
1 2 3 4 5 6 7 8
$ cat /var/lib/kubelet/config.yaml | grep -A 1 DNS clusterDNS: - 10.96.1.10
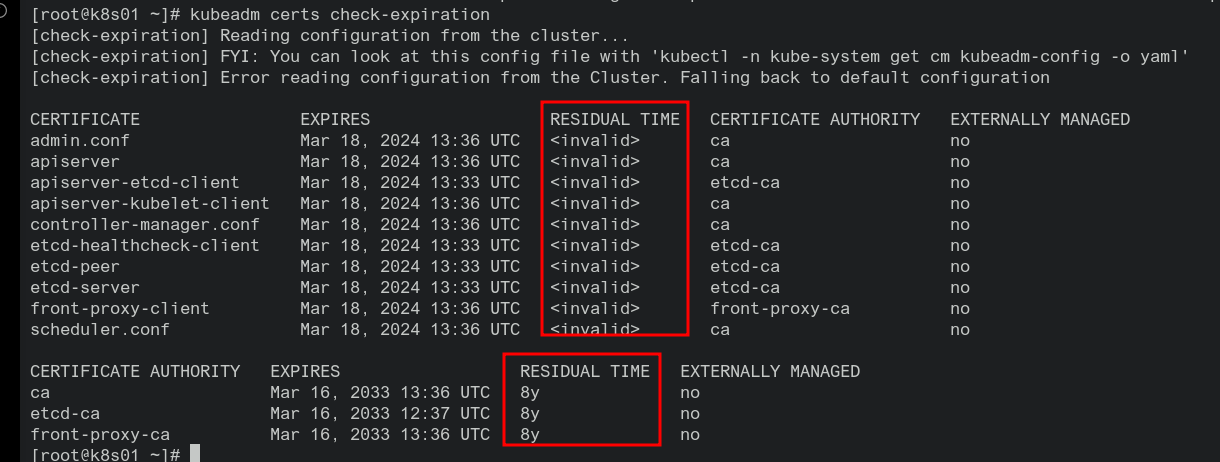
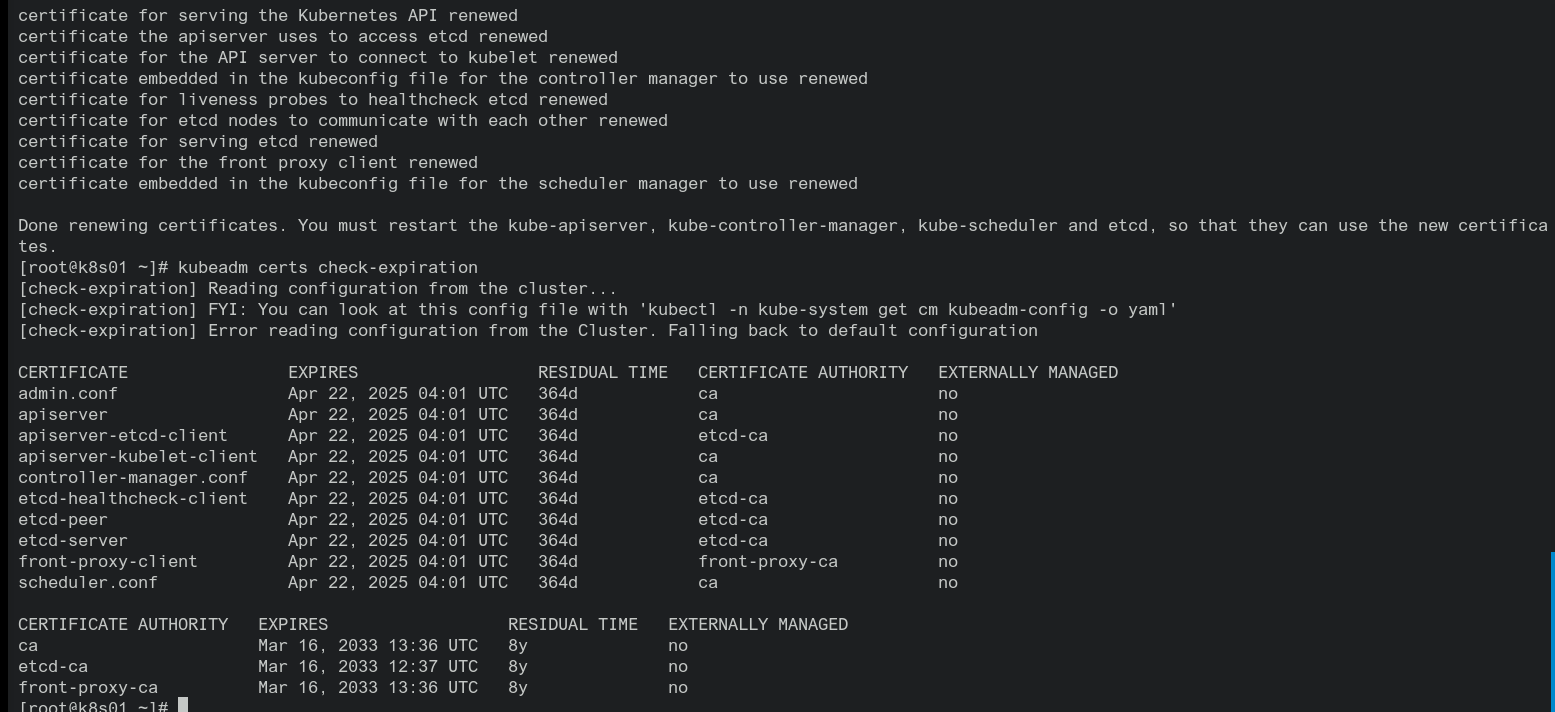
#备份 cp -R /etc/kubernetes/pki /tmp/pki_backup #在所有控制平面节点执行 [root@k8s01 ~]# kubeadm certs renew all [renew] Reading configuration from the cluster... [renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [renew] Error reading configuration from the Cluster. Falling back to default configuration
1 2 3
systemctl restart kubelet
cp /etc/kubernetes/admin.conf $HOME/.kube/config
memcache.go:265] couldn’t get current server API group list: the server has asked for the client to provide credentials error: You must be logged in to the server (the server has asked for the client to provide credentials) 没有认证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
❯ kubectl get nodes E0422 14:21:12.120751 102845 memcache.go:287] couldn't get resource list for metrics.k8s.io/v1beta1: the server is currently unable to handle the request E0422 14:21:12.126398 102845 memcache.go:121] couldn't get resource list for metrics.k8s.io/v1beta1: the server is currently unable to handle the request E0422 14:21:12.130678 102845 memcache.go:121] couldn't get resource list for metrics.k8s.io/v1beta1: the server is currently unable to handle the request E0422 14:21:12.132943 102845 memcache.go:121] couldn't get resource list for metrics.k8s.io/v1beta1: the server is currently unable to handle the request NAME STATUS ROLES AGE VERSION k8s01 Ready control-plane 399d v1.26.1 k8s02 Ready control-plane 399d v1.26.1 k8s03 Ready control-plane 399d v1.26.1 k8s04 Ready <none> 393d v1.26.1 k8s05 Ready <none> 393d v1.26.1 k8s06 Ready <none> 393d v1.26.1 k8s07 Ready <none> 179d v1.26.1 k8s08 Ready <none> 178d v1.26.1 ❯ kubectl top node Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)