ollama
1
| ❯ docker pull m.daocloud.io/ollama/ollama
|
1
| docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
|
ollama.yaml
docker compose -f ollama.yaml up
version: '3.8'
services:
ollama:
container_name: ollama
image: ollama/ollama:latest
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- 11434:11434
volumes:
- "/mnt/ssd/local-data/ollama:/root/.ollama"
download models https://ollama.com/library
1
| docker exec -it ollama bash
|
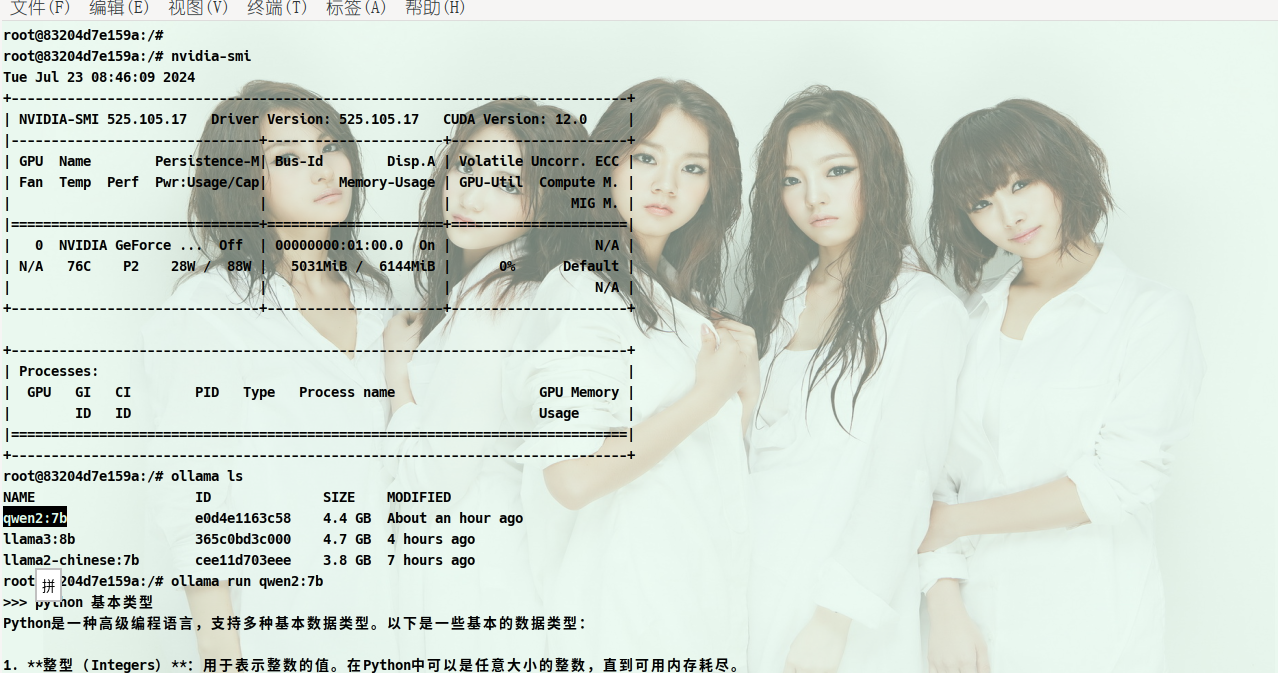
webui
不带ollama
1
| docker pull m.daocloud.io/ghcr.io/open-webui/open-webui:main
|
ollama-webui.yaml
ollama-webui
version: '3.8'
services:
ollama:
container_name: ollama
image: ollama/ollama:latest
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- 11434:11434
volumes:
- "/mnt/ssd/local-data/ollama:/root/.ollama:rw"
open-webui:
container_name: webui
image: open-webui:0.3.10
depends_on:
- ollama
# runtime: nvidia
# environment:
# - NVIDIA_VISIBLE_DEVICES=all
extra_hosts:
- "host.docker.internal:192.168.122.1" # 添加主机名
ports:
- 12345:8080
volumes:
- "/mnt/ssd/local-data/open-webui/data:/app/backend/data:rw"
带ollama
1
| docker pull m.daocloud.io/ghcr.io/open-webui/open-webui:ollama
|
webui.yaml
webui
version: '3.8'
services:
open-webui:
container_name: webui
image: open-webui:ollama
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- 12345:8080
volumes:
- "/mnt/ssd/local-data/ollama:/root/.ollama:rw"
- "/mnt/ssd/local-data/open-webui/data:/app/backend/data:rw"
点击打赏

会心一笑