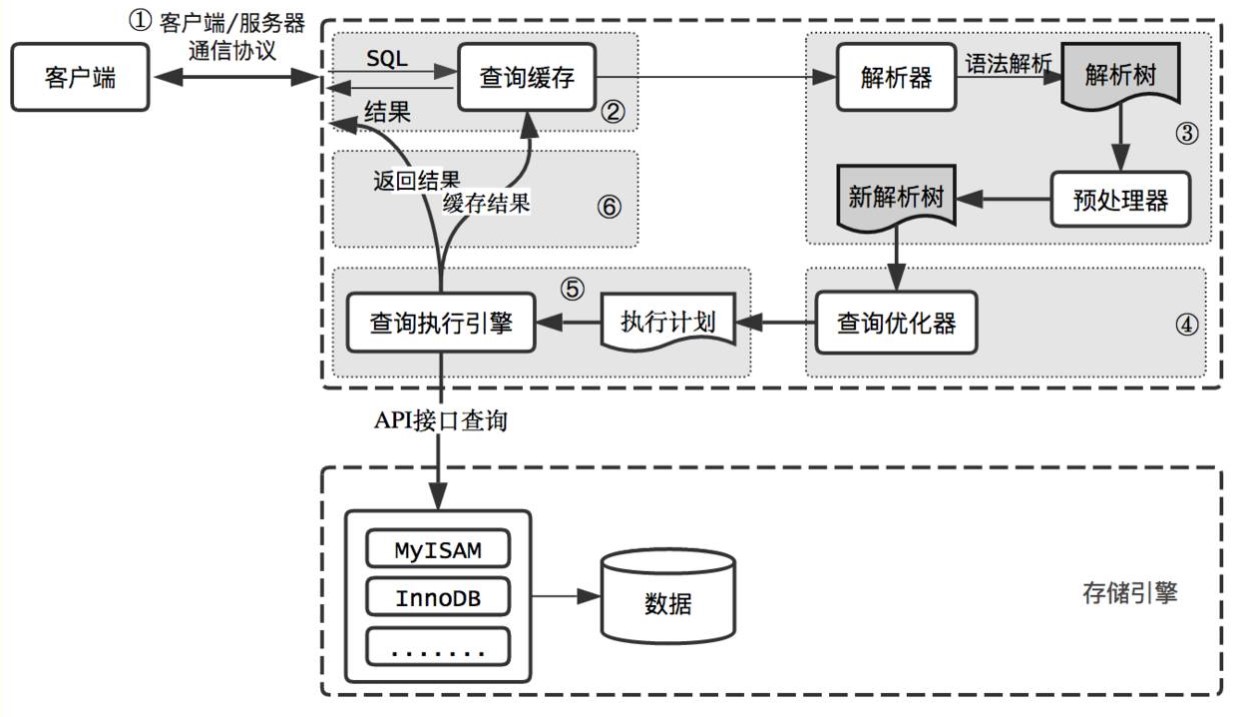
mysql查询过程
客户端与服务端通信协议
“双半工” 在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生
在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用SELECT
*以及加上LIMIT限制的原因之一。
查询缓存
解析一个查询语句前,如果缓存是打开的,那么mysql会检查这个缓存语句是否命中缓存中的数据,如果命中,在检查用户权限后直接返回缓存中的结果,这种情况下,查询不会被解析,不会生成执行计划,更不会执行
mysql将缓存放在一个引用表 (类似hashmap)
利用哈希值索引
,这个哈希值通过查询本身,数据库,客户端版本号等一些影响结果计算得到,2个查询不同(空格,注释等),不会命中
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果都不会被缓存
函数NOW()或者CURRENT_DATE()
包含CURRENT_USER或者CONNECION_ID()
缓存何时失效
查询缓存系统会跟踪查询语句中涉及的每个表,如果这些表(结构或数据)发生变化,那么和这张表相关联的所有缓存数据都将失效。
如何写操作都会导致缓存失效
如果查询缓存非常大或者碎片很多,带来很大系统消耗,甚至系统僵死一会儿,查询对缓存的额外消耗不仅在写操作,读操作也不例外:
1.任何查询语句开始前必须经过检查缓存,即使这条sql语句永远不会命中
2.如何结果可以被缓存,那么执行完成后会将结果写入缓存,也会带来额外消耗
并不是什么情况下查询缓存都会提高系统性能,缓存和失效都会带来额外消耗,只有缓存带来资源消耗大于本身消耗资源时,才会给系统带来性能提升
优化:
多个小表代替大表,避免过度设计
缓存空间大小设置
,几十兆
批量插入代替循环单条插入
通过SQL_CACHE
和SQL_NO_CACHE控制某条语句是否需要进行缓存
写密集型应用不要打开缓存,QUERY_CACHE_TYPE 设置 DEMAND
,只有加入SQL_CACHE的查询才会走缓存
缓存如何使用内存?
缓存如何控制内存的碎片化?
事务对查询缓存的影响?
语法解析和预处理
mysql通过 关键字 将sql语句进行解析并生成一颗对应 解析树
过程解析器主要通过语法规则来验证和解析(关键字,关键字顺序是否正确)
预处理 会根据mysql规则进一步检查解析树是否合法 (数据表,列是否存在)
查询优化
经过解析和预处理的语法树被认为合法,并且有优化器将其转化成查询计划;
一般一条查询有多种查询方式,返回相同结果,优化器会选择最好的执行计划
查询当前会话的 last_query_cost 值来计算当前查询的成本
1 | show status like 'last_query_cost' |
这些统计信息包括:每张表或者索引的页面个数、索引的基数、索引和数据行的长度、索引的分布情况等等。
MySQL 和我们想的不一样(我们执行时间短,mysq
值认为选择它认为成本小的,并不意味执行时间短)
驱动表
:mysql中指定了连接条件时,满足查询条件的记录行数少的表为驱动表;如未指定查询条件,则扫描行数少的为驱动表。mysql优化器就是这么粗暴以小表驱动大表的方式来决定执行顺序的。
STRAIGHT_JOIN功能同join类似,但能让左边的表来驱动右边的表,能改表优化器对于联表查询的执行顺序
查询优化器是一个非常复杂的部件,它使用非常多的优化策略来生成一个最优执行计划:
1.重新定义表关联顺序(多表关联查询时,并不一定按照SQL指定顺序进行)
STRAIGHT_JOIN只适用于inner join,并不使用与left join,right join
1 | select t1.* |
2.优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值)
3.提前终止查询 (分页limit )
4.优化排序(单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序)
查询执行引擎
在完成解析和优化后,MySQL会生成对应执行计划,查询执行引擎根据执行计划指令依次执行得出结果。
整个过程通过调用存储引擎实现接口(handler
api)每一张表一个handler实例表示,优化器可以根据这些实例接口来获取表的相关信息,包括列名,索引统计信息
查询过程:
客户端向MySQL服务器发送一条查询请求
服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
服务器进行SQL解析、预处理、再由优化器生成对应的执行计划
MySQL根据执行计划,调用存储引擎的API来执行查询
将结果通过tcp协议进行传输返回给客户端,同时缓存查询结果
