集群
doc https://www.rabbitmq.com/docs/man/rabbitmqctl.8
1 | [root@rabbitmq-2 ~]# rabbitmqctl stop_app #停止节点 |
cluster_status
1 | rabbitmqctl cluster_status |
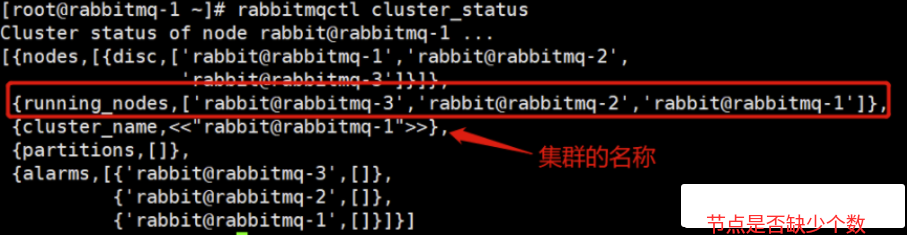
发生了网络分区
关注rabbitmqctl cluster_status字段 的partitions
模拟故障
1 | iptables -A INPUT -p tcp --dport 25672 -j DROP |
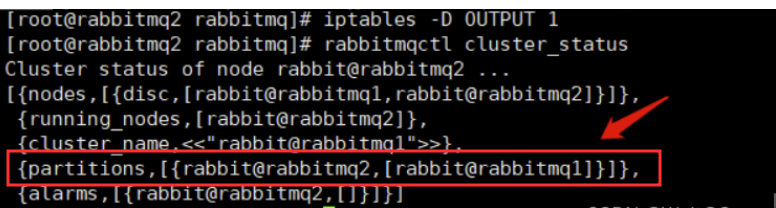
节点2 日志
Network partition detected
xx-xx-x 18:41:32.196 [error] <0.2225.0> ** Node rabbit@rabbitmq1 not responding **
** Removing (timedout) connection **
xx-xx-x 18:41:32.197 [warning] <0.2858.0> Management delegate query returned errors:
[{<9600.1663.0>,{exit,{nodedown,rabbit@rabbitmq1},[]}}]
xx-xx-x 18:41:32.197 [info] <0.2613.0> rabbit on node rabbit@rabbitmq1 down
xx-xx-x 18:41:32.288 [info] <0.2613.0> Node rabbit@rabbitmq1 is down, deleting its listeners
xx-xx-x 18:41:32.289 [info] <0.2613.0> node rabbit@rabbitmq1 down: net_tick_timeout
恢复,确认序号
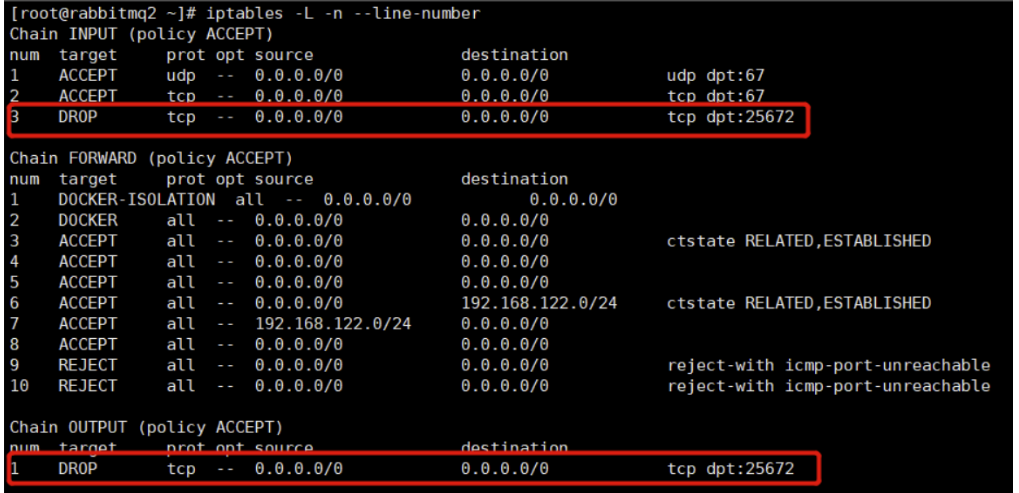
1 | iptables -D INPUT 3 |
进程
rabbitmqctl list_queues
rabbitmqctl list_queues name messages_ready messages_unacknowledged
恢复
手动
重启的方法建议使用 rabbitmqctl stop_app 和rabbitmqctl start_app
自动
RabbitMQ集群分区处置模式设置:
cluster_partition_handling 这个选项有三个可能的值:ignore, autoheal, pause_minority。
ignore: 这是默认设置,意味着RabbitMQ在网络分区发生时将无视网络分区,每个分区将独立运作,分区解决后将要耗费很长时间来同步数据。
autoheal: 这个设置会在发生网络分区时,强制节点从最大的分区(copying its state)中自我恢复,这个过程称为“healing”,healing过程结束后可即刻恢复服务。(最常用的设置,通过RabbitMQ自行恢复)
pause_minority:这个设置会在网络分区发生时,检测哪个分区的节点最多,然后暂停节点较少的分区。这可能会导致RabbitMQ服务暂停,但是当分区修复后,服务可以立即恢复。
1 | # /etc/rabbitmq/rabbitmq.conf |
